
In unserem Blogbeitrag “Wieso automatisierte DB-Schema-Migrationen?” haben wir dir gezeigt, wieso automatisiert laufende DB-Schemaänderungen eine tolle Sache sind. Thematisiert wurden dabei auch zwei mögliche Zeitpunkte zum Ausführen: Beim Deployment und Nebenläufig. Wie diese Änderungen jetzt noch möglichst geräuschlos über die Bühne gehen, erfährst du hier!
Vorgehensweisen
Im Kern geht es darum, die Gestalt von n Datensätzen von Form A in Form B zu bringen. Aber hier fangen die Fragen schon an:
-
Wer greift eigentlich alles auf meine Anwendung zu?
- Richtige Anwort: möglichst nur Instanzen meines eigenen Systems
- Jeder Fremdzugriff macht Schemaänderungen (oder eigentlich alle größeren Änderungen, Last und Sperren nicht vergessen), schwieriger
- Integration via DB ist ein Anti-Pattern
-
Ist n die Anzahl aller Sätze oder reicht eine Untermenge?
-
Muss die Form B physisch in Form geänderter Bits&Bytes auf Platte liegen oder würde eine VIEW in der neuen Form für Lesezugriffe ausreichen?
-
Sind auch alle Datensätze schon in Form A oder muss auch von C nach B migriert werden?
-
Wie ermittle ich ein sinnvolles n ?
-
Wie ermittle ich die nächsten n Sätze effizient?
-
Reicht mein Zeitfenster überhaupt, um die Migration durchzuführen?
Alle Datensätze auf einen Schlag von A nach B umschreiben
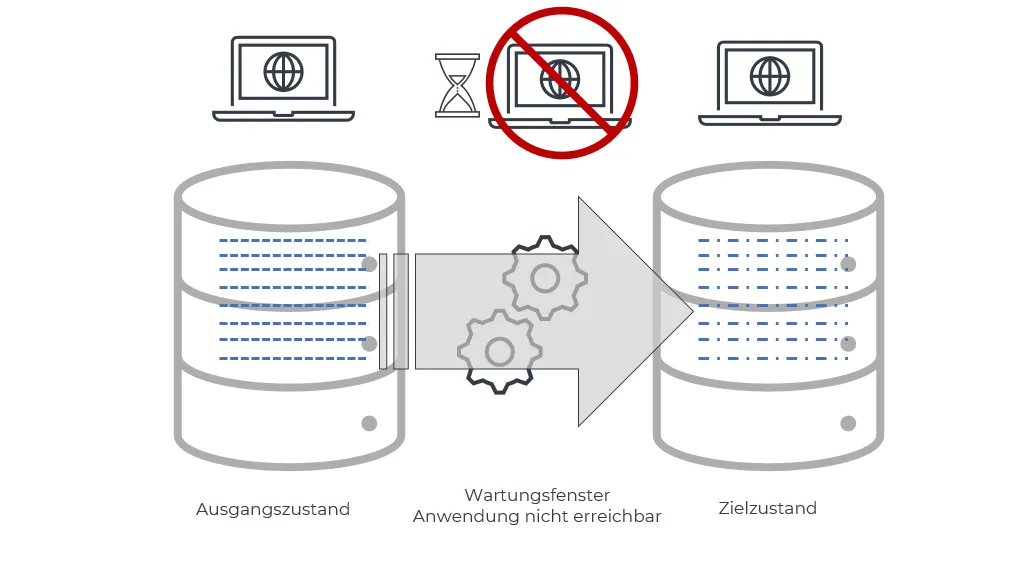
Dies ist der einfachste Fall und aus meiner Sicht auch der anzustrebende, wenn es denn möglich ist. Augen zu und durch sozusagen.
⚠️ Damit alle Datensätze auch wirklich in Form A vorliegen, müssen etwaige vorherige Migrationen vollständig abgeschlossen sein.
Wenn Daten phyisch migriert sind, ist das Lesen einfach. Und das ist letztlich das Ziel. In PostgreSQL eine neue Spalte mit DEFAULT-Wert einzufügen schreibt die Tabelle nicht um, aber beim Lesen dichtet PostgreSQL den genannten Wert für die neue Spalte hinzu, wenn er nicht ausdrücklich geschrieben wurde.
Wenn das nicht die DB für einen tut, müsste eine VIEW o.ä. herhalten und u.a. aktuell gehalten werden. Diese View beschreibbar machen, ist auch Arbeit. Lässt sich das vermeiden, hat man es bei dieser und auch folgenden Änderungen leichter.
Wenn die Anwendung mal kurz weg sein darf, ist die Migration schnell geschrieben. Und häufig ist ein “kurz weg” auch möglich. Lief die Anwendung in den letzten Wochen gut, lässt einem ein SLA mit Mindestverfügbarkeit ein bisschen Zeit: 99,9% Verfügbarkeit lässt im Monat fast eine Dreiviertelstunde Ausfallzeit zu, selbst bei 99,999% bleiben 26s übrig, die, wenn sie nicht ungeplant und ungewollt verloren gegangen sind, auch für kurze geplante Umstellungen genutzt werden können. Wenn man nicht 99,99999% versprochen hat, kann man sich also Aufwand sparen und kleine Umstellungen mit kurzem (!) Aussetzer ausrollen.
Änderungen auf alle Zeilen einer Tabelle sperren diese für andere Leser:innen und das für die Dauer der gesamten Transaktion. Die Tabelle ist also nicht verfügbar. Unterstützt die DB keine Transaktionen, sieht die Anwendung alte und neue Fassung nebeneinander (siehe nächster Punkt). Hier wollen wir das aber vermeiden. Also muss die Anwendung pausiert sein.
Reicht diese Zeit nicht, führt kein Weg daran vorbei, die Gleise unter dem rollenden Zug auszuwechseln. Dieser Vergleich hinkt jedoch etwas, im Gegensatz zu Zügen, die so fahren sollen, wie sie sind, kann in unserem Fall auch die Anwendung angepasst werden. Wiederholung: “fremde” Anwendungen haben auf einer DB eigentlich nichts verloren, das Integrationsmuster “gemeinsamer DB-Zugriff” im Zusammenspiel mit DB-Schemaänderungen ist nur was für Masochisten und solche, die persönlich vom Nutzen dieses Musters derart überzeugt sind, dass sie auch bereit sind, dafür zu leiden.
Nur neue Datensätze physisch von A nach B migrieren
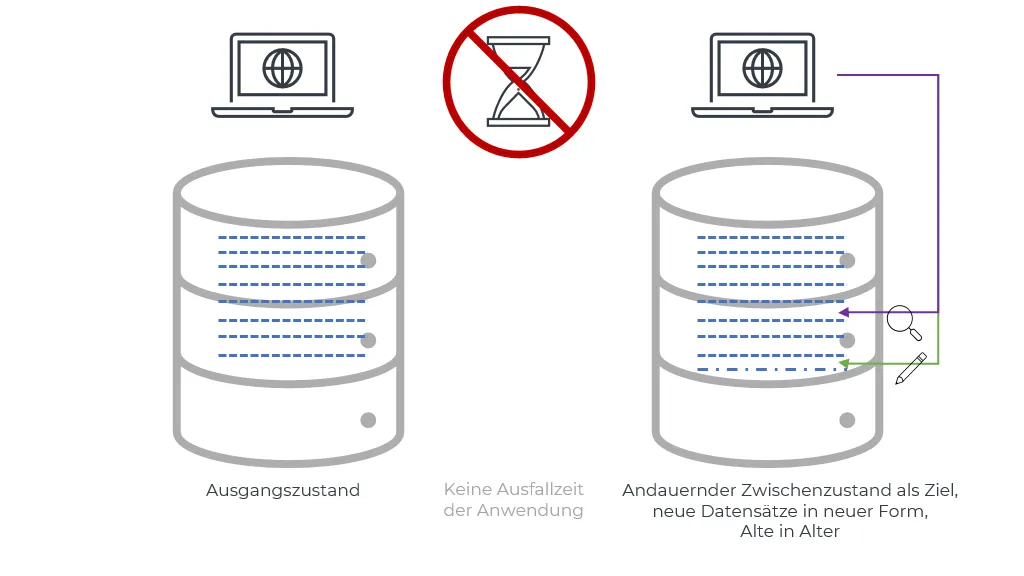
In diesem Fall muss das Schema nur vorbereitet werden, es werden keine Datensätze angefasst. Die Anwendung muss also sowohl altes wie auch neues Schema kennen: Das alte Schema, um vorhandene Datensätze weiterhin lesen zu können und, wenn die Anwendung während der DB-Schemamigration nicht heruntergefahren wurde, müssen auch neue Anwendungsinstanzen noch im alten Schema (zusätzlich) schreiben, damit noch alte Anwendungsinstanzen die neuen Datensätze lesen können. “Zero Downtime” kostet leider auch.
Wenn es noch eine weitere Vorversion des Schemas gibt, muss die Anwendung auch dieses lesen und ggf. schreiben können (usw.). In NoSQL-Dokumentendatenbanken ist häufiger anzutreffen, dass alte Schemata zumindest gelesen werden können. Ein festes Schema für alle Datensätze in der DB gibt es hier nicht (wohl aber in der Anwendung, die wissen muss, wie die Daten zu interpretieren sind), Solange die Anwendung alte Datensätze noch lesen kann, müssen sie nicht im Rahmen einer Migration angefasst werden.
Der Preis ist eine kompliziertere Anwendung, die verschiedene Versionen lesen können muss und dann jeweils in der neuesten Version schreibt.
Mehr oder weniger geschenkt bekommt man hier die Bedingung, dass die DB auch von der Instanzen der alten Version der Anwendung beschrieben werden kann, da diese schlicht neue unmigrierte Sätze (im alten Format, was die Anwendung lesen können muss) erzeugt. Das wiederum ermöglicht, dass die DB-Änderung eingespielt werden kann, während die Anwendung läuft, es müssen also keine 2 Deployments synchronisiert werden.
⚠️ Je nach DB und Schemaänderung kann auch ohne Datenänderung eine kurzzeitige exklusive Sperre auf die ganze Tabelle (für Metadaten o.ä.) nötig sein. Weiter unten wird beschrieben, dass selbst das gefährlich sein kann.
Zusätzlich noch alle alten Datensätze migrieren
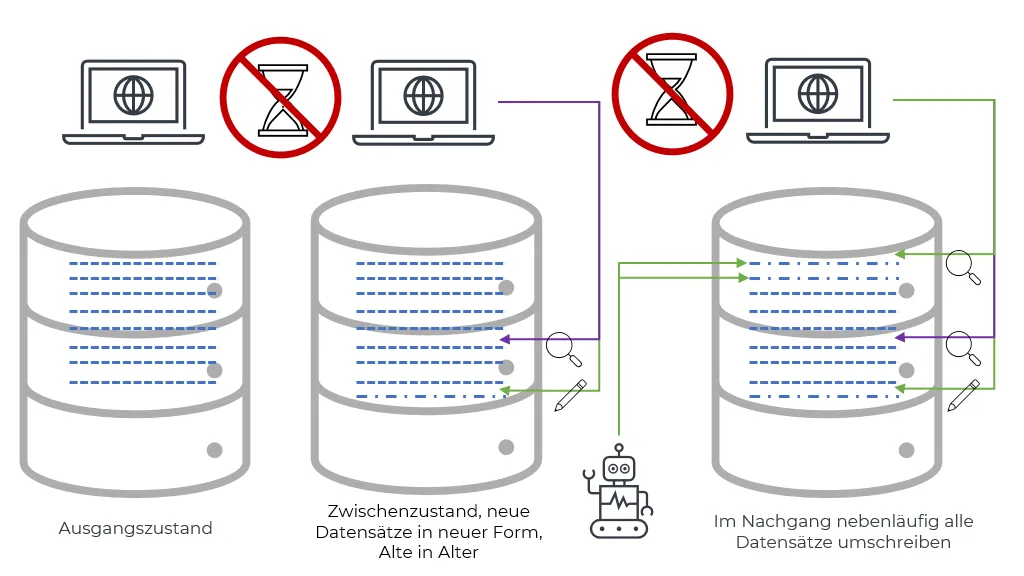
Um nicht zu viele Schemaversionen gleichzeitig unterstützen zu müssen, kann ein Hintergrundjob laufen, der nach und nach Datensätze vom alten Schema ins Neue umschreibt.
Hauptvorteil ist, dass nach dessen Abschluss weder Anwendung, noch zukünfige Migrationen auf nicht mehr existente Schemata Rücksicht nehmen müssen. Der Hauptnachteil wurde im vorherigen Abschnitt als Vorteil genannt: Es müssen jetzt doch nicht alle Datensätze angefasst werden, die DB wird “nicht in Ruhe gelassen”.
Diese Datensätze müssen jedoch erst gefunden werden. Alle auf einen Schlag umstellen scheidet aus, da hätte man ja wieder das Problem einer Riesentransaktion, die alles sperrt und lange dauert. Und ggf. viel Plattenplatz beansprucht. In Datenbanken, die MVCC verwenden (wie PostgreSQL), ist ein UPDATE als Einfügen einer neuen Version und als gelöscht-Markieren der vorherigen Version zu verstehen. Es existiert also jede geänderte Zeile doppelt. Auch müssen bei einer Replikation in einem Riesenrutsch alle Zeilen übertragen werden, was die Replikation folgender Transaktionen blockieren kann. Erschwerend kommt hinzu, dass Transaktionen je nach DB zum Zurückrollen ähnlich lange brauchen können, wie für die eigentliche Ausführung. Ein elendig langsamer Not-Aus-Knopf ist nichts, was man im Störfall braucht!
Für die Umstellung jedes einzelnen Datensatzes/Zeile die DB gesondert aufzurufen, lässt die Netzwerklatenz stark hervortreten, zudem können extrem viele Transaktionen eine DB unnötig belasten. Daher empfiehlt es sich, jeweils mehrere Sätze als Paket oder Block ein einmal umzustellen (z.B. über eine WHERE-Bedingung, die auf mehrere Sätze zutrifft). Wie groß ein Paket werden soll, ist (leider) erst durch Ausprobieren und messen herauszufinden (am besten auf einer mit Produktion vergleichbar dimensionierten DB). Länger als ein paar Sekunden sollte die Abarbeitung eines Paketes nicht brauchen, das ist schon ein Zigfaches der Aufruflatenz und des Transaktionsoverheads der DB.
Bei verteilten Datenbanken oder reinen Key-Value-Stores müssen ggf. einzelne Aufrufe abgesetzt werden (denn wenn in einer verteilten DB jeder Satz auf einem anderen Rechner liegen kann, gibt es kein “innerhalb des DB-Rechners”). Bei Datenbanken mit Partitionsschlüssel wie Cassandra, bietet es sich an, partitionsweise umzustellen (konkreter ein BATCH, welcher innerhalb einer Partition sogar noch ein alles-oder-nichts bietet (aber standardmäßig auf 50kb beschränkt ist)).
Nächstes Problem: Herausfinden, welche Datensätze das nächste Paket ausmachen. “Die nächsten 5000 Unmigrierten bitte!”. Aber welches Kriterium bestimmt die “nächsten” und woran erkenne ich “Unmigrierte”?
Wenn die Hintergrundumstellung zeitnah zur Schemaänderung angestoßen wird, wird es weit mehr unmigrierte Sätze geben, als migrierte. Es ist also wichtiger, flink die “nächsten” Sätze zu bestimmen, als dabei möglichst einfach die bereits migrierten herauszufiltern (das hilft natürlich!). Also: Finde mir schnell die nächsten mindestens n Sätze und werfe aus dieser Menge alle bereits migrierten raus, so dass n übrig bleiben.
Ein “full table scan” um die nächsten Sätze zu finden, ist bei einer großen Tabelle (und eine solche haben wir, wenn wir nicht auf einmal umstellen können), langsam und setzt massiv Lesesperren, ist also nichts, was wir wollen.
⚠️ Es muss also ein Index genutzt werden!
Dieser Index muss nicht UNIQUE sein, da insbesondere, wenn die Eigenschaft “unmigriert” nur anhand von Spalten, die nicht im Index sind, ermittelt werden kann und die Abfrage eh nicht mehr “index only” ist.
Jetzt braucht man nur noch einen Programmrahmen, welcher Paket für Paket migriert und sich (nicht nur im flüchtigen Arbeitsspeicher) merkt, wie weit er gekommen ist. PL/SQL, T-SQL oder PL/pgSQL können das mit einer Hilfstabelle sein, manchmal muss es auch ein eigenständiges Programm/Skript sein (für MySQL und andere DBs, welche keine Skripte ausführen können). Es soll vorgekommen sein, dass Entwickler:innen die paketweisen SQLs von Hand auf Produktion sogar ohne Fehler und Datenmissbrauch ausgeführt haben, aber nein, bitte nicht!
Erstellen einer Schattentabelle und späteres Umschalten
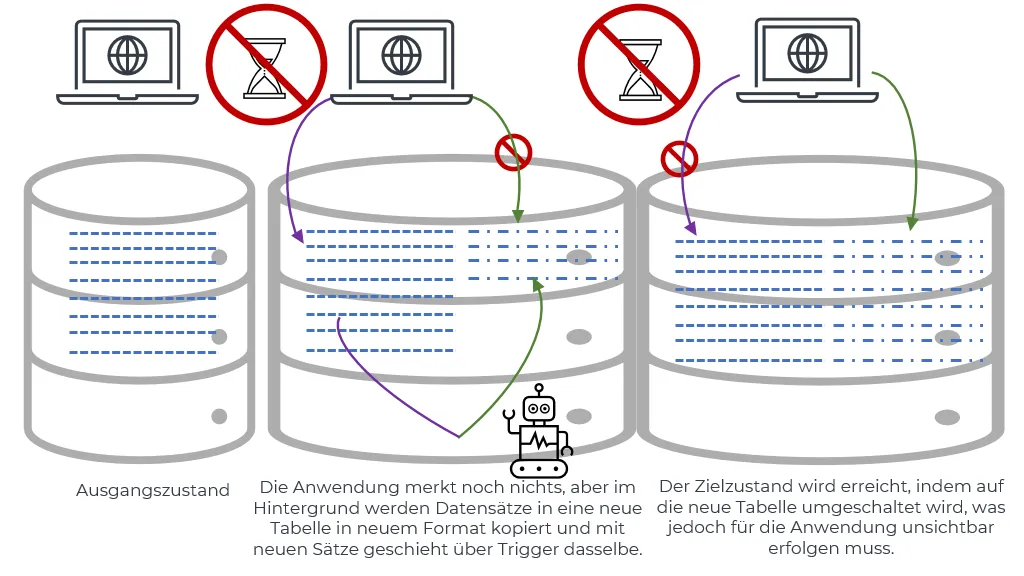
Mit diesem Muster werden die Datensätze in neuer Form in eine neue, der Anwendung noch unbekannte Tabelle geschrieben. Erst zum Abschluss der Migration tauschen alte und neue Tabelle die Rolle/den Namen, so dass die Änderungen auf einen Schlag sichtbar werden.
Großer Vorteil ist hier, dass die Anwendung die meiste Zeit über nichts von den Schreibzugriffen im Hintergrund merkt und sie weiterlaufen kann. Zu beachten ist jedoch die erhöhte Last auf der DB und dass der Hintergrundjob ggf. Lesesperren setzt. Daten in eine indexlose Tabelle einzufügen und die Indices am Schluss en bloc zu erstellen, ist schneller, als die Indices vorab anzulegen. Dies funktioniert jedoch nur, wenn zur Ermittlung der als nächstes umzukopierenden Daten aus der Ausgangstabelle kein “full table scan” auf der Schattentabelle ausgeführt wird (weil z.B. nach id sortiert gelesen wird und in einer weiteren winzigen Tabelle vermerkt wird, welche ids schon umkopiert wurden).
Unbequemerweise geht das Leben weiter und die Anwendung schreibt in dieser Zwischenzeit noch weiter Datensätze in alter Form. Diese müssen natürlich ebenfalls noch umgestellt werden. Wenn man etwas Zeit für ein Wartungsfenster hat und man darin schnell die noch nicht umkopierten/migrierten in der Zwischenzeit geänderten Sätze der Ursprungstabelle ermitteln kann, dann kann dieser Schritt mit abschließendem Umbenennen der Tabellen sowie das Umstellen aller Instanzen der Anwendung im Wartungsfenster erfolgen. Lohn dafür ist, dass die Anwendung entweder nur mit dem alten oder nur mit dem neuen Schema funktionieren können muss. Alternativ dazu könnte ein Trigger auf die Ursprungstabellen eingerichtet werden, welcher “unter der Haube” und “nebenbei” den Satz in die neue Tabelle kopiert/migriert. Das ist zwar DB-seitig komplizierter, verkürzt jedoch das nötige Wartungsfenster drastisch, da dann nur noch 2 Tabellen umbenannt werden müssen und die Anwendung in neuer Version ausgespielt werden muss.
Zero Downtime: unter dem rollenden Zug
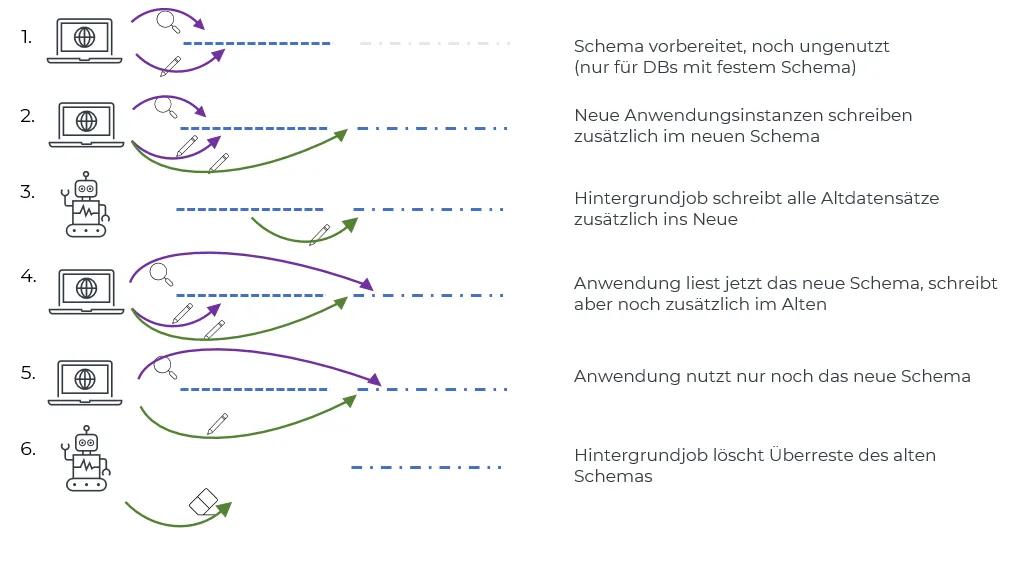
Leider können nicht bei jeder Datenbank Tabellen umbenannt werden (wie bei Cassandra) oder es gibt keine Trigger, mit denen weitere Tabellen rein über DB-Mittel aktualisiert werden können. In solchen Fällen muss die Anwendung ebenfalls angepasst werden. Dieser Ansatz ist im ersten Teil skizziert, im folgenden wird er etwas ausführlicher beschrieben.
-
Kompatible Schemaänderung ohne Datensatzänderungen. Die Anwendung läuft weiter, als ob nichts wäre.
-
Nach und nach alle Instanzen der Anwendung anpassen, so dass sie schreibend das neue Schema nutzen, aber dieses (noch) nicht lesen.
-
Hintergrundjob, welcher Datensätze umschreibt. Nach dessen Abschluss gibt es keine Altsätze mehr.
-
Anwendungsinstanzen umstellen, so dass sie nur noch das neue Schema lesen, aber das Alte noch schreiben (aus Rücksicht auf noch laufende Alt-Instanzen).
-
Wenn alle Instanzen das neue Schema lesen, eine neue Anwendungsversion ausspielen, welche das alte Schema nicht mehr schreibt/kennt. Das ist erst der Zielzustand!
-
Hintergrundjob/-Migration, welcher veraltete Teile des Schemas aufräumt. Genutzt werden diese Teile nicht mehr, aber Sperren oder Last können die Anwendung weiterhin stören, Vorsicht ist also auch hier geboten.
Dieser Ansatz ist wesentlich aufwändiger und es gibt mehr Fehlermöglichkeiten. Und dennoch kann man ihn als sicherer betrachten, weil es keine Umstellung mit großem Knall gibt, sondern jeder einzelne Schritt nicht stört (nicht stören darf). Sollte die Anwendung z.B. das neue Schema nicht richtig beschreiben, werden weiterhin nur richtige Daten gelesen und Datensätze und Anwendung lassen sich ohne Downtime beheben.
Was sonst noch zu beachten ist
Lange exklusive Sperren
Gewisse Varianten von ALTER TABLE schreiben die ganze Tabelle neu und brauchen dementsprechend lange. Währenddessen wird die Tabelle exklusiv gesperrt. Damit müssen alle Transaktionen, welche auf diese Tabelle zugreifen wollen, lange warten. Damit fällt dieser Teil der Anwendung (und ggf. noch mehr, siehe unten) garantiert aus. Nicht gut …
Welche ALTER TABLE-Befehle das sind, ist DB- und versionsabhängig. PostgreSQL 11 hat zum Beispiel gelernt, dass ALTER TABLE bla ADD COLUMN blub TEXT DEFAULT 'Pfefferminz'; nicht mehr alle Zeilen umschreibt (weil ein DEFAULT-Wert auch beim Lesen berechnet werden kann), aber ein Postgres 10 konnte das noch nicht.
Exklusive kurze Sperre
Einige ALTERs wie z.B. das Hinzufügen von nullbaren Spalten auch mit DEFAULT-Wert in Postgres brauchen nur eine kurze exklusive Sperre. Für sich genommen, fällt diese sehr kurze Sperre unter normalen Umständen nicht auf.
Dummerweise kann auch so eine kurze Sperre die gesamte DB für längere Zeit blockieren. Da die Sperre exklusiv ist, müssen erst alle gerade laufenden Transaktionen abgearbeitet werden, bevor die exklusive Sperre gesetzt werden und das ALTER TABLE loslaufen kann.
Weitere Transaktionen mit gewünschtem Zugriff auf die betroffene Tabelle reihen sich nach diesem ALTER TABLE in die Warteschlange ein, egal, ob sie nun lesen oder schreiben wollen, da eine exklusive Sperre alles sperrt.
Laufen alle Transaktionen schnell durch, bleibt alles im grünen Bereich. Lief jedoch eine langlaufende Abfrage, bevor das ALTER TABLE gestartet wurde, muss dieses lange warten. Weitere, selbst nur lesende Abfragen, welche sonst parallel zum Langläufer liefen, müssen jetzt jedoch auf das ALTER TABLE warten. Und das, wie oben genannt, auf den Langläufer.
Ein Teil der Anwendung reagiert jetzt schon nicht mehr.
Hinzu kommt, dass Verbindungen zur DB normalerweise über Connection Pools begrenzter Größe laufen. Bei vielen unnatürlich lange brauchenden Transaktionen ist dieser schnell mit diesen gefüllt und weist weitere Aufrufe ab (oder steckt sie in eine Warteschlange). Damit sind auch alle anderen DB-Abfragen, die über diesen Connection Pool laufen, blockiert und der Schaden vergrößert sich.
⚠️ Also vorher auf Langläufer achten (auch grundsätzlich!) und insbesondere DB-Änderungen nicht gleichzeitig mit diesen ausführen. Eine andere Gegenmaßnahme ist die Aufteilung der Anwendungen in verschiedene Schotte (Bulkheads) mit getrennten Connection Pools oder als gesondert laufende Instanz. Wenn diese nicht auf die gesperrte, oder genauer, zu sperrende Tabelle zugreifen, können sie ungestört weiterlaufen.
Unterschiedliche Datensatzversionen während des Umschreibens
Wie oben beschrieben, migrierte Datensätze müssen erkannt werden können. Wenn einfach nur der Bruttopreis mit 1,07/1,19 multipliziert wird, weil der Mehrwertsteuersatz gesenkt wurde, dann sieht man dem Ergebnis nicht an, ob es bereits migriert wurde.
Speicherplatzverbrauch
Wie bereits erwähnt, mit MVCC oder einer Hintergrundstabelle wird doppelt Speicher benötigt. Wann dieser wieder frei und an das Betriebssystem “zurückgegeben” wird, hängt von den Aufräumläufen und -Strategien der DB ab.
Performance-Beeinträchtigungen durch Last
Hintergrundmigrationen belasten die DB (CPU und oder I/O), diese sollte also noch genügend Leistungsreserven haben, um den Normalbetrieb gewährleisten zu können.
Laufzeit absolut
Langsam, ggf. gedrosselt laufende Hintergrundmigrationen mögen zwar einen Normalbetrieb erlauben, aber bevor die nächste Migration anlaufen kann, muss die vorherige fertig sein. Eine wochenlange Umstellung kann die Anwendungsentwicklung also ausbremsen.
Nebenläufige Migrationen auf unterschiedlichen DB-Objekten sind grundsätzlich möglich, sorgen jedoch für aufaddierte Last und müssen besonders sorgfältig auf gegenseitige Verträglichkeit geprüft werden.
Nebenläufige Indexerstellung
Zumindest PostgreSQL bietet CREATE INDEX x CONCURRENTLY an, was eine Tabelle nicht während der Indexerstellung sperrt, aber insgesamt für mehr Last sorgt (z.B. 2 “full table scans”) und entsprechend länger dauert.
Fazit
DB-Schemata lassen sich ändern und sogar ohne Tränen, wenn vorher ausreichend Hirnschmalz hineingesteckt wurde. Hoffentlich hilft dir dieser Artikel beim Vorbereiten der nächsten DB-Schemaänderung, der du dann wesentlich gelassener entgegenblicken kannst.